八股要点简章
Redis
-
缓存穿透(大量无效数据,无法命中缓存,导致 DB 宕机):空写入、Bloom 过滤器
-
缓存击穿(某个 key 的缓存失效后,恰有大量访问发送来,过多的数据库请求导致 DB 宕机):互斥锁(从 DB 请求数据写入缓存的时候,阻塞其他请求)、逻辑过期(发现过期数据,则上锁向数据库请求更新,但不会删除。其他读取请求会返回过期的数据)
-
缓存雪崩(同时有大量 key 过期,或者 Redis 服务宕机):TTL 随机、使用集群(针对宕机)、添加多级缓存(例如增加一层 Guava 缓存)、业务限流
-
双写一致(与 DB 的写入同步问题):延迟双删(仍有脏数据风险)、共享锁、排他锁(保证数据强一致)、异步方案(使用 MQ(消息队列)中间件、canal 中间件)
-
持久化:RDB(定期做内存快照,磁盘占用小,但系统资源占用高,会丢失数分钟的数据)、AOF(记录命令,磁盘占用大,数据丢失小,一般只占用磁盘 I/O,AOF 重写时占用 CPU 和内存)以上两种方案一般同时使用,配合进行。
-
数据过期策略:惰性过期(访问时判断是否过期,是则删除)、定期删除(SLOW模式 FAST 模式。SLOW 模式默认执行频率10hz,每次耗时不超过25ms,可在redis.conf配置。FAST 模式在每次事件循环都会尝试执行,间隔不小于 2ms,耗时不超过 1ms。)
-
数据淘汰策略:noeviction(Redis 的默认策略,不淘汰数据,内存不足时直接报错)、xxx-LRU(最少最近算法,保留热点数据,适用于无明显季节性的数据)、xxx-LFU(最少频率算法,淘汰最近访问频率低的数据,适用于短时间高频访问的数据)
-
分布式锁:setnx(SET if not exists,该命令会返回 ok/nil 代表是否成功设置。范例:SET lock1 thread1 NX EX 10。其中 EX 表示超时时间,避免死锁)、redission(看门狗机制监控线程运行状态,自动为锁续期。尝试获取锁时可以自动阻塞等待。同线程可以复入锁。底层仍然是执行 setnx 命令,也可以用 lua 脚本原子性地执行多个命令。)
-
集群(一主多从模式,主节点负责写操作,从节点负责读操作。集群可以提高并发能力、避免单个节点宕机造成的缓存雪崩):全量同步(第一次建立主从连接,或进行灾难恢复时进行的同步。① 从节点携带自己记录的 replicationId 和 offset 发起同步请求。② 主节点比较自己和从节点的的 replicationId 判断是否是第一次连接,replicationId不同则是第一次连接,连接建立后,主节点将自己的 replicationId 和 offset 同步给从节点。③ 主节点开始 bgsave,并且在这期间执行的命令会被存到缓冲区 ④ 主节点将生成的 rdb 文件和命令缓冲区的命令发送给从节点,从节点依次初始化数据)、增量同步(从节点定期向主节点发送同步请求,将 offset 落后的部分进行同步,避免网络抖动和短暂失联造成的同步失效)
-
哨兵式集群(哨兵会自动监控所有节点,当主节点宕机,会自动选举新的主节点,并通知连接中的 Redis 客户端):监控机制(一般会有 3 个以上的哨兵同时参与监控,它们所有 Redis 节点进行心跳检测,发现未响应,则称该节点主观下线。超过半数的哨兵检测到节点主观下线,则认为该节点客观下线。)、选举规则(offset 高的优先,与主节点断开时间过长的排除,配置的 priority 小的优先)、脑裂(哨兵与主节点因网络分区问题短暂失联,因而选举了新主节点。然而客户端已经在老主节点写入了数据。老主节点被降级为从节点后,这些数据将会丢失)
-
分片集群(① 集群中存在多个主节点,每个主节点存不同的数据。② 主节点各自有从节点。没有哨兵,主节点互相进行心跳检测。③ 请求可以自动在主节点之间路由,客户端可以连接任意的主节点。这些特性使得集群的数据储存量提升、高并发写能力提高):哈希槽(将 16384 个哈希槽分配给所有主节点。对 key 值计算哈希,模 16384 得到的结果,对应的主节点就是数据写入的节点。)
-
其他特性:① Redis 是单线程的、纯内存操作的数据库,无需进行磁盘 IO,无需多线程上下文切换,速度很快。② Redis 使用多路 IO 复用模型,同时监控多个 socket,只有当某个 Socket 可读、可写的时候才得到通知、读取数据。避免 CPU 在网络 IO 上浪费等待时间。③ Redis 6.0 之后,在解析命令、连接回应、命令回复这三个地方引入了多线程,进一步加快了速度。
MySQL
-
性能分析:① 使用开源工具 Arthas、Skywalking 等。可以生成类似火焰图的接口响应时间概览,可判断 SQL 查询是否严重拖慢响应、SQL 查询的具体执行时间。 ② 慢查询日志。可以配置 MySQL 自动记录执行耗时超过一定时间的命令。一般只在调试阶段使用,运营阶段此功能会浪费资源。③ 在 SQL 语句前加上 EXPLAIN 可以执行性能分析,其中包括使用的索引、查询类型(根据主键、唯一索引、范围扫描、全盘扫描等)
-
索引:
InnoDB 主要使用两种 B+ 树索引:
聚簇索引(Clustered Index):
叶子节点保存完整的数据行。
非叶子节点保存索引值和指向子节点的指针。
辅助索引(二阶索引)(Secondary Index):
叶子节点保存主键值(而不是完整数据)。
非叶子节点仍然只保存索引值和指针。
回表查询:通过二阶索引取得主键,再通过主键获取数据。
B+ 树的优点:① 层级少,每次读写需要进行的 IO 次数 少。② 非叶子节点不储存完整数据,检索时磁盘读写代价小(与 B 树不同,B 树的非叶子节点同时也是数据节点)。③ B+ 树的叶子节点组成双向链表,顺序储存数据,便于扫盘和范围查找。
覆盖索引:在一次查询中使用了索引,并且直接取得了所有需要的列,则称索引覆盖。例如用主键查询任意列、用普通索引查询并返回主键或索引本身。
分页查询优化:深度分页查询 (例如 SELECT * FROM user ORDER BY id LIMIT 900000, 10)将排序 900010 条记录并丢弃掉前面 900000 条,代价很高。可以先进行覆盖索引查询得到主键,然后执行子查询根据主键返回完整数据。
前缀索引:对字符串类键创建索引时,可以截取前缀固定长度作为索引,避免开销过大。
创建索引的原则:
- 对数据量较大、访问较频繁的表创建索引
- 常用于查询条件、排序的字段
- 尽量使用联合索引,可以提高索引覆盖率,避免回表。
- 控制索引数量,如果索引太多,增删改的维护成本会很高。
-
索引失效:① 使用联合索引检索数据时,违反最左前缀(联合索引只会使用前连续 n 个索引)规则。② 使用联合索引检索数据时,范围查询右边的列不能使用索引。③ 条件值进行函数运算或者发生类型转换。④ 使用字符串进行模糊查询,通配符后面的部分会失效。
-
事务:ACID(原子性、一致性、隔离性、持久性)
并发事务问题:
- 脏读:事务读取到另一个未提交事务操作中的数据。
- 不可重复读:事务前后两次读取到的数据不同。
- 幻读:事务执行查询时没有对应数据行,而插入时又发现数据行已存在。
-
隔离级别:
READ UNCOMMITED 事务可以读取其他未提交事务操作中的数据。
READ COMMITED 事务无法读取其他未提交事务操作中的数据,读取会返回未提交事务开始之前的数据。解决脏读问题。
REPEATABLE READ 事务开始后,从第一次读取开始,读取到的数据便不再改变。解决脏读、不可重复读问题。
SERIALIZABLE 事务开始后,读取会对数据行加共享锁,修改会对数据行加排他锁,直到事务提交或回滚后解锁。解决所有并发问题,但效率很低。
MVCC 多版本并发控制:
记录某个行的历史版本,事务根据指定的隔离级别从历史版本中读取可见的版本。本质是读快照,避免读写互斥。
该技术为每个数据行添加隐藏字段:trx_id(事务id,记录生成这个版本的事务 id)roll_pointer(记录上个版本的地址) -
主从分离:
主数据库负责写入操作,从数据库负责读取操作,可以解决高并发读写问题。 -
主从同步:
① 从数据库对主数据库第一次同步时,可以用 mysqldump 先将数据库完整拷贝一次,再建立主从连接。
② 建立主从连接后,主数据库将二进制日志文件发送给从数据库,从数据库的 IO 线程将日志文件保存到中继日志 Relay Log 中,随后重做日志中的新更改。
Java 并发编程
基本并发概念
- 锁升级:
sychronized 关键字通过修改逐步修改被加锁对象的对象头(对象在 jvm 中的内存结构的一部分)中的 mark word,根据低竞争到高竞争逐步改变锁的类型。共有以下三种类型:
- 偏向锁:第一次获取锁时,会使用这种类型。同线程重入锁时,只有第一次获取锁会执行 CAS 操作记录线程号,后续仅通过对比线程号判断锁是否由本线程拥有。性能最好。
- 轻量级锁:第一次尝试竞争时,由偏向锁升级为轻量锁。这种类型的锁会使用 CAS(Compare And Swap)操作尝试改变 Mark Word(即尝试获取锁),否则自旋等待。由于阻塞时不会被挂起,在短等待、低竞争时性能很高,在阻塞和释放时通常纳秒级别内即可完成。
- 重量级锁:竞争激烈或自旋次数达到上限,由轻量锁升级为重量锁。尝试获取重量级锁的线程被阻塞时,会被直接挂起。线程挂起涉及到系统调用,需要切换特权级别,即从用户态切换到内核态,这是一个微秒级别的操作,开销很高。
-
JMM(Java Memory Model, Java 内存模型规范):
JMM 规定:内存被划分为两个区域,一块是线程独立的工作区域,另一块是共享内存区域(主内存)。JMM 制定了一系列读写规范(可见性、内存屏障),确保共享内存和线程独立内存之间数据的同步性和正确性。 -
volatile:
volatile 的特点:确保变量可见性、不确保原子性、内存屏障
内存屏障(Memory Barrier)的详细释义:
- 写操作确保:volatile 写之前的普通写操作不会被重排序到 volatile 写之后。volatile 写之后的读写不会被重排序到 volatile 写之前。
- 读操作确保:volatile 读之后的读操作不会被重排序到 volatile 读之前。读取数据直接从主内存中获取,保证可见性。
- ThreadLocal:
每个线程会在工作内存中维护一个 ThreadLocalMap,ThreadLocal 并不直接储存值,而是作为 Map 的键。
例如,
ThreadLocal<Integer> local = new ThreadLocal<>(new Integer(1));
Thread t1 = new Thread(() -> {
Integer i = local.get();
});
其中 local.get() 的底层其实就是获取当前线程的 ThreadLocalMap,然后以自己作为键获取对应的值。
ThreadLocalMap 可能会发生内存泄露,尤其是在使用线程池时。ThreadLocalMap 对 ThreadLocal 是弱引用,但对值本身是强引用。如果线程消亡,垃圾回收时会自动回收该线程的 ThreadLocalMap,不会发生内存泄露。但是线程池中的线程不会消亡,其中,如果对于键的引用被回收,值将无法被访问,也无法解除引用,这就发生了内存泄露。
- 死锁排查:
当线程 A 拥有锁 A 时,尝试获取锁 B,而线程 B 拥有锁 B 时尝试获取锁 A,就会出现死锁问题,程序卡死,锁 B 和锁 A 也无法释放。
使用 jstack [进程号] 命令可以自动检查是否有死锁发生。
死锁的基本条件(为什么会形成死锁):① 占有时等待:如果一个进程占有了一些资源并请求另一些资源,但由于其他进程占有了它所请求的资源,那么该进程就会等待。同时,该进程仍然持有它已经获得的资源。② 资源不可抢占:资源不能被抢占,只能在进程自愿释放的情况下才能被其他进程获取。③ 循环等待:A 占有资源 α 的同时等待资源 β,B 占有资源 β 的同时等待资源 α,两个线程之间形成了无限长的等待链。
死锁预防:① 并发量不高、执行时间短的时候,可以尝试一次性获取所有资源的锁。② 在线程运行途中遇到需要的资源被占用,主动释放已经占用的资源(如调用 wait 进入等待队列)。③ 制定资源序号,获取资源时按序进行,避免循环等待。
JUC(java.util.concurrent)
-
ReentrantLock:
传统 sychronized 关键字能够对代码块、实例方法和静态方法加锁,实质上是对已有对象、被调用的实例、类对象加锁。而 JUC 的 ReentrantLock 是一个专门的锁类,相比 sychronized 也多了一些可配置的地方,如设置公平锁,获取锁自动超时等。
ReentrantLock 的底层也与 sychronized 不同,ReentrantLock 基于 AQS(AbastractQueuedSynchronizer,JUC 提供的并发同步资源模板) 进行扩展,而 AQS 的底层使用 Unsafe API 提供的 CAS 调用实现自旋锁,避免使用重量级锁。
现代 Java 开发中,只有预期为低并发,或者阻塞时间长(如 IO 密集任务)的情况下,才使用 sychronized 关键字。
高并发情况下,sychronized 的轻量级锁会退化为重量级锁,性能会急剧下降。因此高并发场景下,务必使用 JUC 提供的工具和锁。 -
Condition:
传统 sychronized 的监视者是被上锁的对象本身(上锁的对象与唯一的 Monitor 关联)。当多个业务同时使用同一把锁时,notify 无法定向唤醒执行指定业务的线程。在使用 Lock 加锁时,通过 Lock.newCondition() 方法可以创建并绑定多个 Condition 实例,为特定的业务分配单独的 Condition 实例,可以做到定向唤醒。 -
CopyOnWriteArrayList:
读写分离的集合类。读取时不会上锁,也不会阻塞。修改时上锁,然后复制整个数组,修改完成后替换旧的数组。
修改开销大,因此适合读多写少的高并发场景。 -
ConcurrentHashMap:
在 Java 8 以前,ConcurrentHashMap 采用分段锁,Java 8 以后,采用桶级别锁,总之,有别于对整个实例加锁,这种加锁的方式粒度更小,可以支持不同数据的高并发访问。读取操作大部分不需要加锁。
在更新共享变量时,ConcurrentHashMap 采用 CAS(Compare-and-Swap) 操作来保证原子性,不会导致读写互斥。适合高频读取、低频写入的场景。 -
Callable、FutureTask:
Callable 接口要求实现一个带有返回值的 call 方法,作为业务主体。由于业务需要异步执行,返回值不能当场取得,而是“在未来取得”。因此,要想将 Callable 放到线程中执行,还需要用 FutureTask 将其包装一下。
FutureTask 是一个实现了 Runnable 的包装类,可以被线程直接运行。调用 FutureTask.get() 方法,将导致阻塞直到 Callable 中的业务执行完毕产生返回值。 -
CountDownLatch:
多线程计数器工具,调用 CountDownLatch.await() 会阻塞,直到计数器为 0。 -
CyclicBarrier:
共同屏障,在达到屏障点(计数器达到指定值)之前,线程之间将彼此等待。线程通过调用 CyclicBarrier.await() 使屏障计数器加 1 并开始阻塞等待。 -
Semaphore:
计数信号量,可以用于限制调用某个方法的最大的活跃线程数。Semaphore 在实例化时可以通过参数设置通信证最大值,线程通过调用 Semaphore.acquire() 尝试获取通信证,如果未能获取到则阻塞等待。业务执行完成后,调用 Semaphore.release() 释放通行证。 -
ReadWriteLock:
读时加共享锁,写时加互斥锁。 -
BlockingQueue:
设置队列最大值,如果队列满了,添加元素将会阻塞。如果队列为空,取出元素将会阻塞。有三组 api,分别可以在无法入队和出队时 阻塞、不阻塞、不阻塞并报错。
BlockingQueue 本身是线程安全的。 -
线程池:
线程池中的维护一定量的空闲线程,这些线程不会被销毁,而是处于阻塞状态,等待任务到来。
线程池避免了高密度多线程作业时线程的建立和销毁产生的开销,但是增加了内存占用。如果不涉及 IO,一般建议线程池大小与 CPU 核心数量相同。如果有 IO 操作,则以一定的系数增加线程池大小 CPU 核心数量 * (1 + 阻塞系数)。
线程池的几个参数:核心线程池大小(最小线程数量)、最大线程池大小(最大线程数量)、空闲生存时间、工作阻塞队列、拒绝策略(工作队列满时如何处理)。
- 工作阻塞队列:主要使用 阻塞链表 和 阻塞数组队列。前者在头尾分别加锁,入队和出队不会互斥,效率较高,但是 Node 入队时创建、不能随机访问。后者在出入队时对整个数组加锁,出入队互斥。一般情况下,采用前者即可。
- 拒绝策略又分为:不处理并抛出异常(abort)、由调用者的线程直接执行任务(callerRuns)、不处理无异常(discard)、与最早执行的线程尝试竞争,否则抛弃(discardOldest)
-
ForkJoinTask 分支 和并:
用于将大任务拆分成小任务,然后并行执行小任务。类似于算法中的分治思想,只是在分治的基础上加上并行处理。
常用的两个抽象类:RecursiveTask、RecursiveAction。顾名思义,两者都通过递归拆分任务。前者有返回值,后者没有返回值。
ForkJoinPool:相当于线程池,用于并行执行 ForkJoinTask。调用 ForkJoinTask.folk() 会尝试继续拆分,并放入线程队列等待线程池执行。 -
并行流:
虽然都带有流字,但与 CPU 的流水线架构不同,Java 并行流其实是对原始数据集进行二分拆分,并基于 ForkJoinPool 进行并行运算。
注意!并行流虽然很快,但是可能会改变数据顺序,不适合处理有顺序依赖的数据。
使用并行流进行排序,底层算法是归并排序(或者 TimSort,这是一种归并和插入排序结合的算法),归并算法基于分治思想,很适合并行执行。为什么同样是分治思想的快速排序不适合?因为如果分组不均导致线程负载不均,并行将效率下降。 -
CompletableFuture:
与 FutureTask 类似,都用于执行异步任务。但 CompletableFuture 有各种增强功能,例如任务完成通知(回调)whenComplete、任务编排组合、异常处理 。
JVM
JVM 的内存组成
- 程序计数器:每个线程有自己的程序计数器,指示当前执行的字节码指令的地址。
- Java 栈(虚拟机栈):存储方法的局部变量、操作数栈、动态链接和方法返回地址。每个线程有自己的栈,线程栈还会储存主内存中变量的拷贝。
- 本地方法栈:为本地方法(使用 Java Native Interface 调用的本地代码)提供的栈空间。
- 堆:所有创建的对象实例和数组都分配在堆内存中。堆内存被所有线程共享。
- 新生代(Young Generation):存储新创建的对象。新生代通常又分为三个区域:Eden 区、Survivor 0 区、Survivor 1 区。伊甸区经过 GC 幸存的对象将进入幸存者区。
- 老年代(Old Generation):存储经过多次垃圾回收仍然存活的对象。
- 永久代(Permanent Generation)(JDK 1.7 及以前版本):用于存储类信息、方法数据等。
- 元空间(方法区):(JDK 1.8 及以后版本)用于存储类信息、方法数据、常量、静态变量。这块内存与本地内存性质相似,它是一块本地内存,直接由操作系统分配管理。被所有线程共享。
- 直接内存:这是堆外直接与系统交互的内存部分,需要手动申请和释放,分配回收的成本比较高(涉及到系统调用,需要切换到内核态),但是读写效率很高。
GC
GC(Garbage Collection)中文为垃圾回收机制,是 JVM 主要针对堆的内存清理手段。
垃圾判别算法:
- 引用计数法。该算法认为,没有引用指向的对象,就是垃圾。这种算法无法避免循环引用造成的内存泄漏。
- 可达性分析算法。该算法通过从某个 Root 出发,遍历能够通过引用达到的所有对象,当所有 Root 被遍历完,没有被遍历到的对象则视为垃圾。这是普遍采用的 GC 策略。
垃圾回收算法:
- 标记清除算法:通过可达性分析对对象进行标记,随后清楚未标记的对象。这种算法回收的速度很快,但是会导致内存碎片化。
- 标记整理算法:在标记清除的基础上,将存活的对象向一端移动。这种算法不会导致内存碎片化,但是速度较慢。这种算法用于老年代的垃圾回收,被称为 Major GC,因为老年代的对象存活率高,不会导致大规模整理。
- 复制算法:将内存分为两块区域,一部分放新创建的对象,另一部分放存活的对象,每次对新创建对象的部分进行可达性分析,将存活的对象直接依次放入另一部分内存,从而跳过了对死亡对象的处理。这种算法用于新生代的垃圾回收,被称为 Minor GC。一般新生区每次 GC 会死亡 80% ~ 90% 的对象,因此 Java 默认对新生代区域做出 8:1:1 (Eden、Survivor0、Survivor1) 的划分,Survivor0、Survivor1 会轮流作为存活对象的存储区域。
垃圾回收器:
- Serial Old/New GC 串行垃圾回收器。适用于单核嵌入设备。
- Paralllel Old/New GC 并行垃圾回收器。是 Java 8 默认采用的垃圾回收器,对于新生代,采用复制算法,对于老年代,采用标记整理法。并行指的是回收过程由多个线程执行,回收仍然产生 STW。
- CMS GC 并发、标记-清除算法的垃圾回收器。这种回收器旨在尽可能缩短 STW 时间,它经历四个阶段:初始标记(标记 GC 根)、并发标记(标记可达)、重新标记(程序在并发标记阶段创建或修改的引用需要重新标记)、并发回收(使用标记清除算法,会产生内存碎片)。其中初始标记和重新标记会产生较短的 STW。在碎片过多或者并发清理的内存不足则会触发 Full GC。
- G1 GC 是 Java 9+ 默认的回收器,全称是 Garbage First GC。G1 的堆内存分代不再是物理上的,而是逻辑上的。它将堆内存分为若干 Region,这些 Region 初始为空闲区域,在运行时被按需分配给各个逻辑上的分区(Eden、Survivor0/1、大型对象存储区、老年代区)。对于 Eden、Survivor0/1,采用复制算法,To Region 是空闲 Region,From Region 在回收完成后释放为空闲 Region。当老年代内存超过阈值时(默认时 45%),开始并发标记(并发标记结束后也需要重新标记处理漏标对象),然后根据事先设定的 STW 最大值,优先选择存活数量少的老年区释放。与此同时,会对 Eden 区和 Survivor 区也进行回收,选出新的 Survivor 并晋升达到存活次数的对象。这个过程是 G1 特有的 Mixed GC。如果垃圾回收的速度不足以释放足够的空间,会触发 Full GC。
- ZGC GC 是超大型堆 JVM 使用的低延迟回收器。垃圾回收全程几乎全部并发,STW(Stop The World) 时间很短,适用于超大堆、低延迟场景。缺点是多线程调度会产生很高的 CPU 开销,复杂的设计也导致内存占用升高
其他
- JIT编译器:JVM 会将热点代码从字节码编译成本地机器代码,提高运行效率。
- 强引用、软引用、弱引用、虚引用:强引用的对象只要能被 GC Root 找到,就不会被 GC 自动回收;只有软引用的对象在一般 GC 时也不会被回收,只有在 GC 后内存仍然不足时,被 Full GC 回收;只有弱引用的对象在 GC 时会被直接回收;虚引用在引用对象被 GC 后会进入引用队列,在专门的 Reference Handler 线程进行回收,主要用于释放外部资源,如直接内存。
- JVM 常用的调优参数:
- 设置堆空间大小 -Xms 堆初始大小 -Xmx 堆最大大小。这两个参数一般设置为一样的值,避免堆收缩产生不必要的开销。
- 虚拟机栈大小 -Xss。每个线程都会分配一个如此大小的栈。一般设置为 256K 或者 512K,默认是 1M。
- 幸存者区比例 -XXSurvivorRatio,默认是 8,代表 Eden : Survivor0 : Survivor1 = 8 : 1 : 1。一般默认即可。但是如果发现 Full GC 的次数异常多,应该适当调大幸存者区的大小,避免幸存者太多时直接晋升到老年区。
- 幸存者晋升阈值 -XX:MaxTenuringThreshold 默认 15。取值范围 0 ~ 15。
- 设置垃圾回收器 -XX:+UseG1GC 这个例子启用 G1 GC。
- 调优工具:VisualVM 可以可视化监控线程、内存的情况。当发现内存飙升时,可能是出现内存泄漏问题,可以生成一个内存dump(内存快照),并导入 VisualVM 进行分析。当发现 CPU 占用居高不下时,可能原因是线程陷入死循环,也可能是并发数量太多。通过 ps H -eo pid,tid,%cpu | grep [进程号] 可以列出所有线程以及各自占用 CPU 的情况,通过 jstack [进程号] 可以查看所有线程的栈,从而定位死循环。如果发现线程总数太大,使用线程池或者Semaphore(信号量)对线程总数进行限制。
Spring
IoC 控制反转
Inversion of Control,是一种设计思想,旨在解决现代软件开发整体耦合度过高,时常出现牵一发而动全身的问题。此外,对于需求可能时常变更的情况,由于对象依赖的控制权在负责本业务的程序员手中,程序员需要时常根据需求修改业务,如果引入 IoC,程序员将,将减少程序迭代的次数。
一下图片描述了 IoC 的作用:
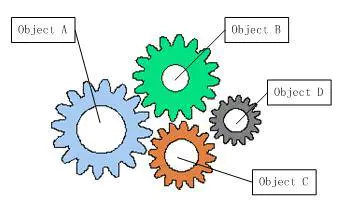
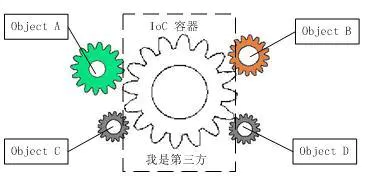
DI(Dependency Injection )依赖注入,是 IoC 的实现方式之一。在没有 DI 的情况下,我们也可以使用面向对象和程序过程实现 IoC。
在 Spring 中,使用容器实现控制反转。
AOP
AOP 为 Aspect Oriented Programming 的缩写,意为:面向切面编程。所谓切面,就是我们对一个纵向的代码(业务过程),进行横向的抽取,抽取出来的切面可以在不涉及本质的情况下进行单独更改,而不需要修改全部业务。例如日志记录、性能统计、事务管理等。而这些横切关注点往往散布在不同的方法和类中,它们就可以进行横向抽取,避免高耦合造成的维护成本过高。
在 OOP 中,我们可以使用代理模式,使对象在不修改原始代码的情况下增加功能。但是这需要我们手动实现代码。在 Spring AOP 中,Spring 提供了一套自动代理的实现,帮助我们解放双手。
Bean
Bean 是由 Spring 容器创建和管理的对象,对象的管理权由容器掌握,就是 IoC 的基本思想。
- Bean 的装配:
所谓装配,就是指 Bean 的构造、配置、依赖注入、最后缓存的过程。对于构造和配置需要的参数,Spring 提供了使用 xml 配置和使用注解两种方式。对于依赖注入,除了 xml 配置和注解以外,Spring 也支持通过名称或类型进行自动注入。 - Bean 的获取
Spring 要求每个 Bean 有不重复的 id(字符串)。在获取 Bean 时,我们只需要从 Spring 容器中通过 id 获取 Bean,使用接口进行引用。例如:
UserService userService = ApplicationContext.getBean("userService");
- 循环依赖 和 三级缓存:
循环依赖是指,Bean A 有一个属性需要 Bean B 注入,而 Bean B 有一个属性需要 Bean A 注入。如果不引入特别的机制进行处理,创建 Bean A 或 Bean B 的时候,将陷入死循环。
Spring 通过三级缓存解决这个问题。在 ApplicationContext 使用的 DefaultListableBeanFactory 中,维护了三个 Map:
SingletonFactories 称为工厂池,如果一个 Bean 还未被引用,它的工厂会先进入这个缓存中。
earlySingletonObjects 称为半成品池,如果一个 Bean 被引用了,则通过工厂制造它,然后放进这个缓存中,下一次引用将直接从这里获得。
SingletonObjects 称为单例池,存储已经完成构造过程的完整 Bean。 - Aware 接口
框架一般具有高度封装性,其底层 API 和辅助属性我们无法轻易获取,但是并不意味着框架完全不提供这类方法。Spring 框架提供了 Aware 接口,它会在合适的时机将 API 和附属属性注入并通知。
常用的 Aware 接口:

Web 应用三层结构
在开发 Web 应用时,按照习惯,会对程序进行三层结构分层:
- DAO(Data Access Object) 层,负责与数据源对接。一般都是原子操作。
- Service 层,对一个或多个DAO进行的再次封装,提供较为复杂、能够直接使用的接口,所以这里也就不会是一个原子操作了,需要事务控制。
- Controller 层,客户端的交互界面,接受客户端的数据,传给Service处理,接到返回值,再传给客户端。
Spring AOP
Spring AOP 支持使用 JDK 动态代理,也支持使用 CGLIB 动态代理。前者在代理目标实现了接口的情况下使用,而后者在代理目标没有实现接口的情况下使用。Spring 会自动判断使用哪一个代理实现。
一个典型的 AOP 使用场景是日志实现,比如对于各种资源加载方法执行时间统计、对于业务代码的异常捕获、输出等。
此外,Spring 提供了健壮的数据库事务实现,也是基于 AOP 对业务代码进行增强。
其他
Gradle
相比传统构建工具(Maven 等)的优势:
- 支持增量构建、构建缓存,即项目中未改变的部分可以不必重新构建。
- 支持并行执行。Gradle 会分析任务的依赖,自动并行执行不互相依赖的任务。
- 配置缓存,无需每次构建都重新解析 build.gradle 等配置文件
- Daemon 进程(守护进程)。Gradle 默认使用 Daemon 进程,在后台保持 JVM 的运行,节省了每次构建的 JVM 的启动时间。
RabbitMQ
RabbitMQ 架构:
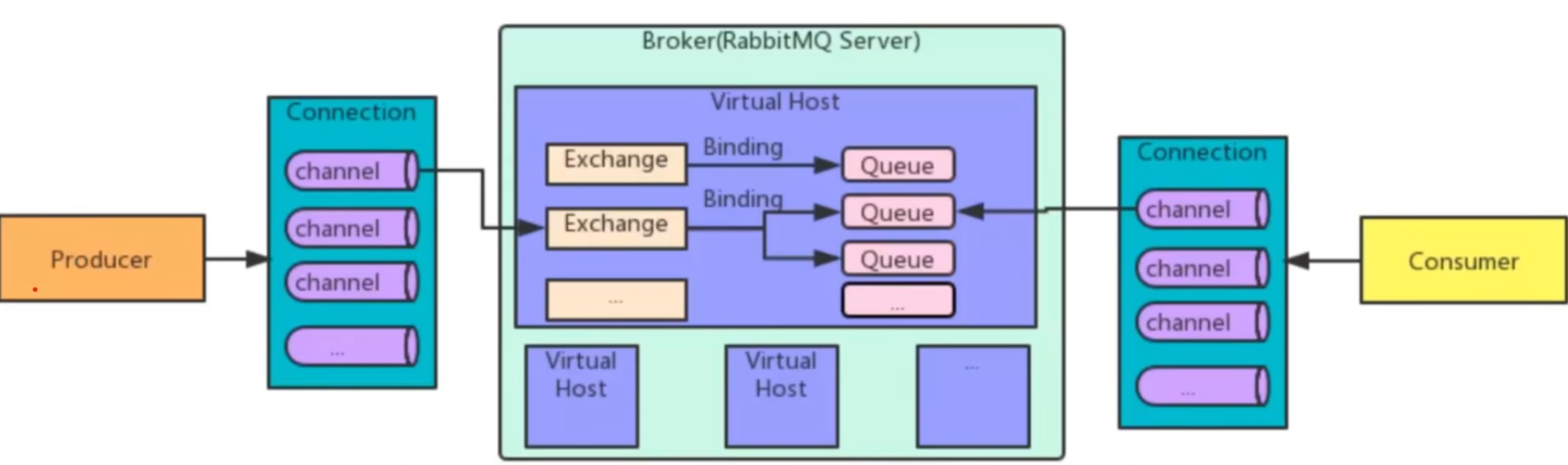
几种不同的交换机:
直连交换机(1->1 匹配)、主题交换机(通过通配符1->n 匹配)、扇出交换机(1->n 直接群发)、头部交换机(用的少,性能比较低)
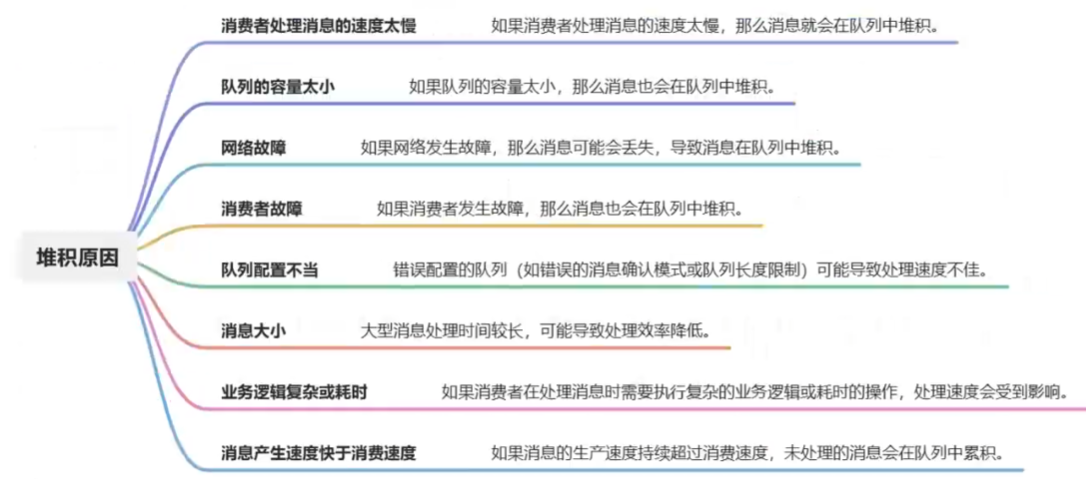
解决消息堆积:
为什么用 RabbitMQ:
- 解耦消息生产和消息消费,这样两端可以分别横向扩展。
- 异步推送,加快响应速度。
- 削峰填谷,减少突发流量带来的压力。
备忘录
面试官您好,我是魏宇强,目前就读于南京航空航天大学,现在是大三在校生。我对编程很感兴趣,初中时第一次接触 c++,学习基础的编程知识、语法和算法知识,后来在高中参加了 NOIP 提高组,取得了省赛二等奖的成绩。过去的3年大学生活中,我也积极参加了许多非课内的项目,大部分是一些其他服务软件的插件开发,在这个时期我开始学习 Java,并对于互联网后端开发有了一些整体认识。我喜欢日常整理和积累,在阅读和探索之后会使用 markdown 记录技术文章,以供自己和其他人复习或者学习。我也积极与一些前辈保持良好的社交关系、关注了许多技术大牛的公众平台,以求获得学习和实践经验。我希望能在实习岗位能够更进一步,与专业人士一起工作,希望能够取得让自己和其他人都能满意的成果。以上就是我的简介。
消息系统的设计要点:
幂等性设计:确保多次投递和重试不产生重复消息。 → 雪花算法生成 ObjectId,存在缓存,消费时查询缓存避免重复消费。
RabbitMQ Confirm:使用发布确认确保消息可靠投递。 → 任务列表指针,每次收到 ACK 使指针 +1;
消息聚合
小程序:
登录模块,通过微信授权服务器授权登录的方式。授权后,向用户发放 jwt 登录令牌。
消息系统,使用 websocket 做消息推送,RabbitMQ 作为消息生产和消息发送之间的中间件,创建死信队列作为失败重试的手段。
预约系统,可以创建预约项目、发送预约申请、审批预约的系统,使用 MySQL 储存预约项目和预约等数据,并使用 redis 做缓存。按照日期、时间排序、分页。
技术要点:每一个预约项目在过了预约 deadline 之后,需要从数据库中移除然后归档,我一开始是考虑使用延时队列的方式去做,后来在网上查阅资料后了解到这种方式有一些缺点,例如会增加内存开销(RabbitMQ 原生不支持延时队列,需要安装一个插件。插件使用的是一个内存调度器)、增加系统复杂度。大部分厂商做这种功能都是使用分布式任务调度的方式,比如使用 Quartz。在这个项目里由于设计上就是单点的应用,因此我自己手动实现了一个定时批处理过期预约项目的功能,每隔一段时间从数据库中查询出过期的项目,归档到日志并且做了过期通知,最后从数据库中删除。
博客:
文章搜索:支持使用 MongoDB 内置的倒排索引搜索(英文),也支持 ES (IK 分词器),有一个简单的向 ES 推送新内容的机制。
订阅通知:使用 JavaMail API 向邮箱服务器发送邮件,RabbitMQ 作为消息队列,起到中间缓存和削峰填谷的作用。
文章页面:使用 markdown 解析器渲染文章,显示评论和引用数。
技术要点:搜索页面的翻页功能是我比较头疼的功能。根据我的观察,大部分相关度搜索网站为了避免深分页的技术成本和维护开销,都做了最大结果条数的限制,例如百度、搜狗都有这种限制。因为相关度搜索无法使用游标翻页。我的相关度搜索页面也使用了这种方式。此外,我还做了根据时间排列文章、根据分类排列文章的页面,这些就使用了 es 的 search_after 做了游标翻页,前端做了一个下拉加载的功能。